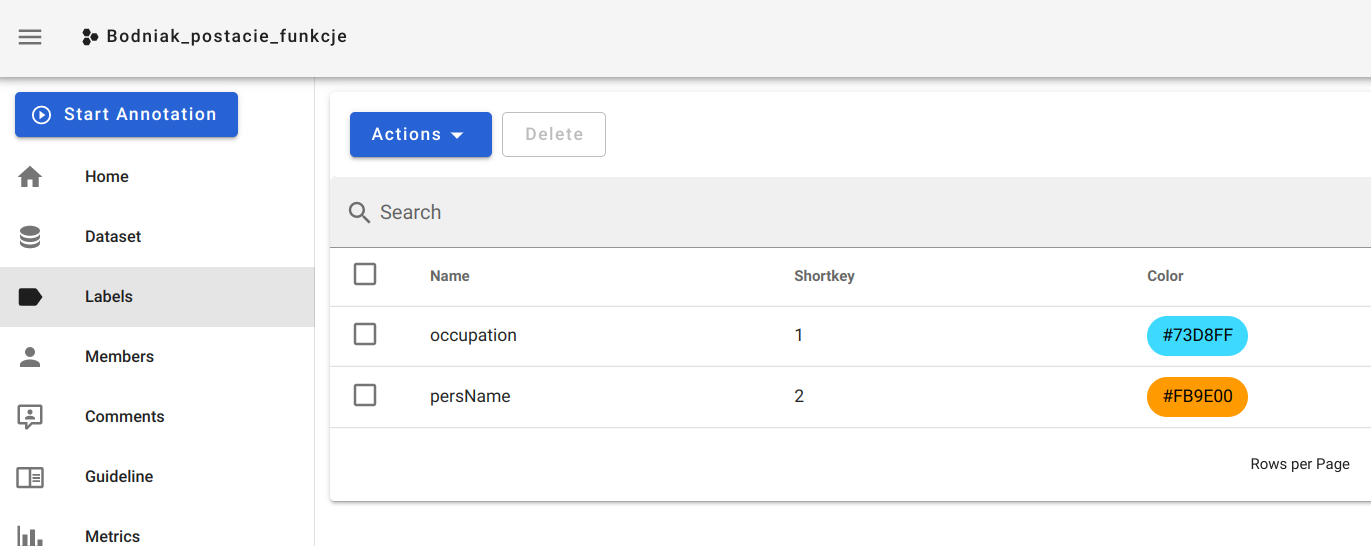
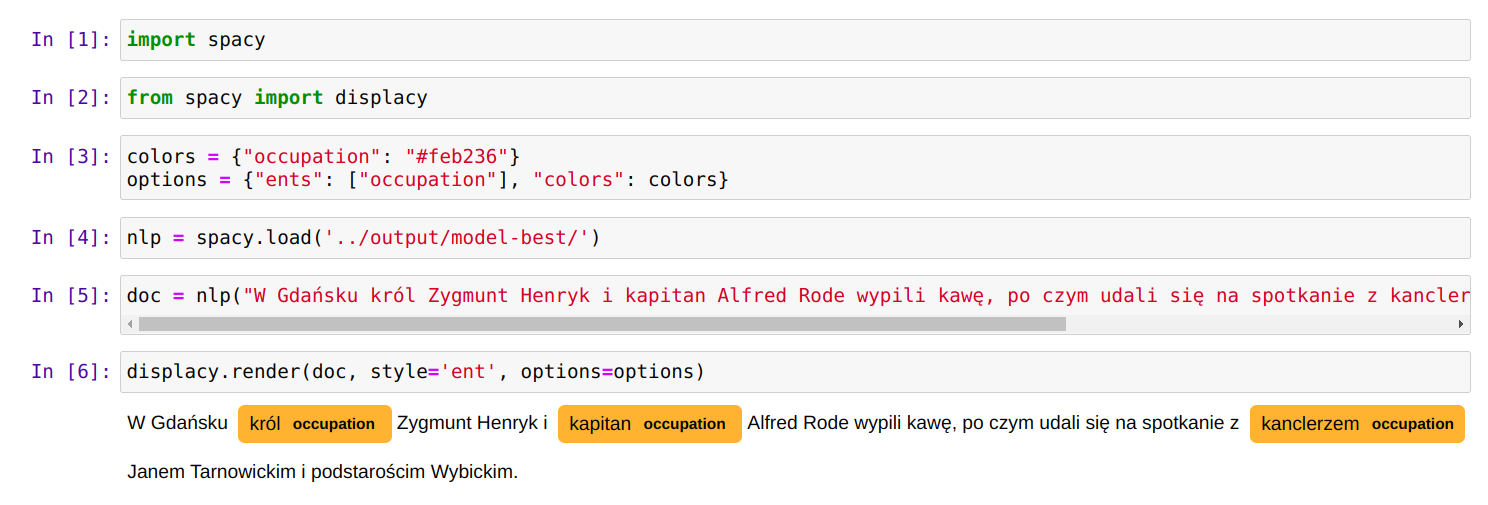
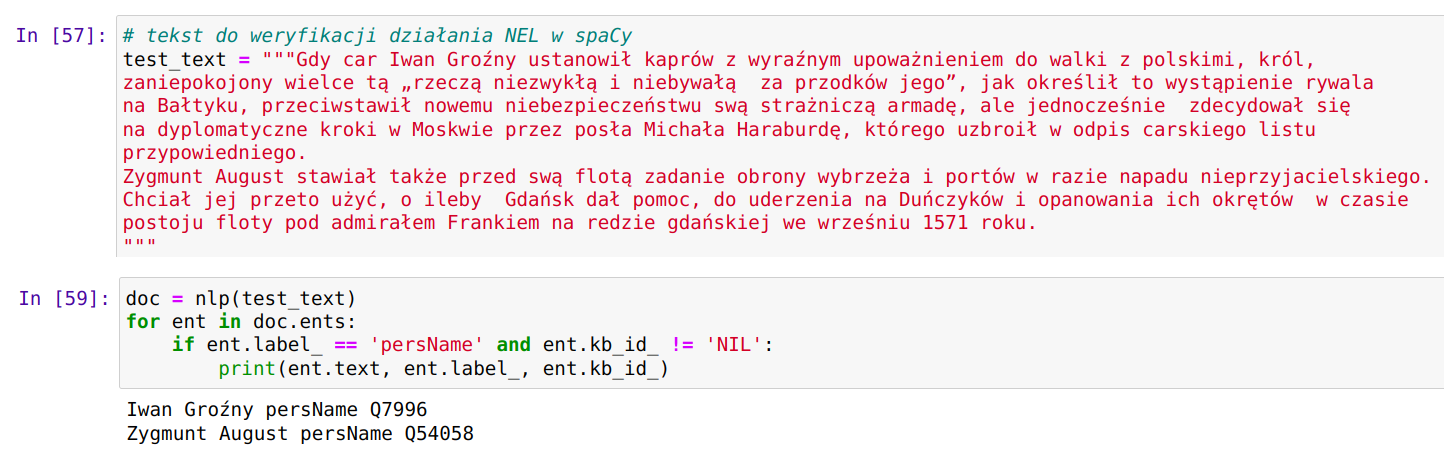
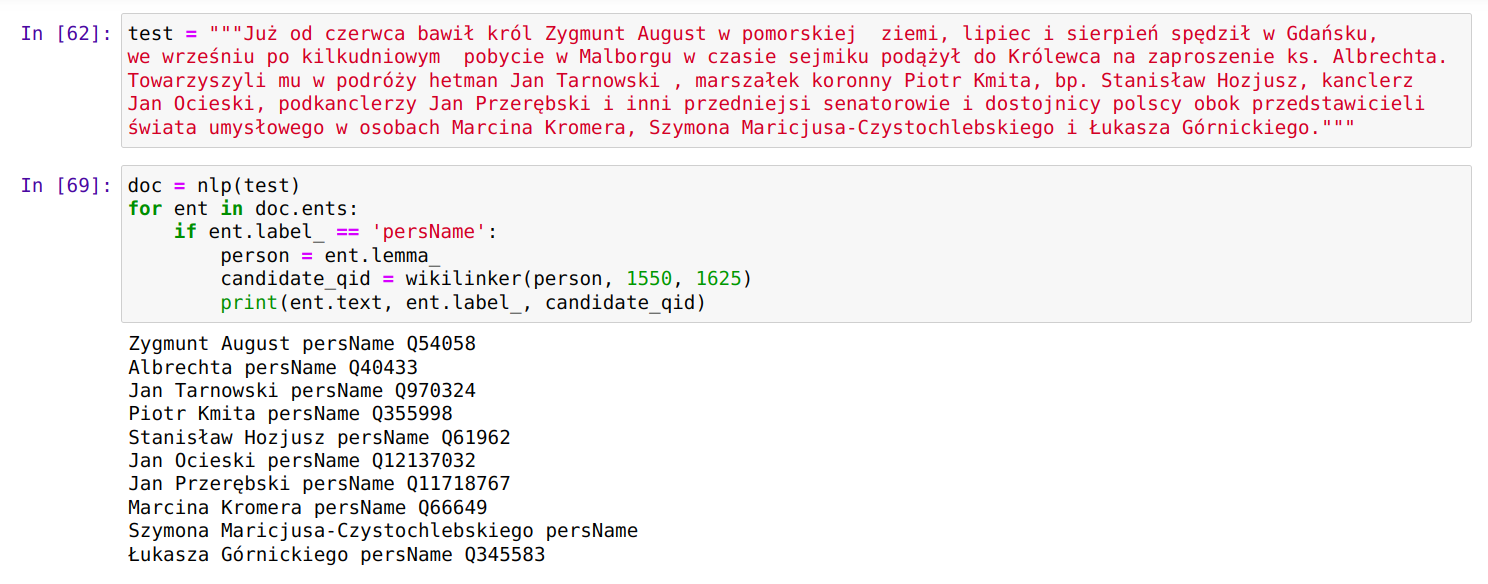
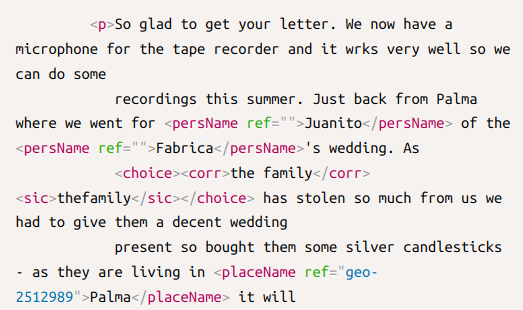
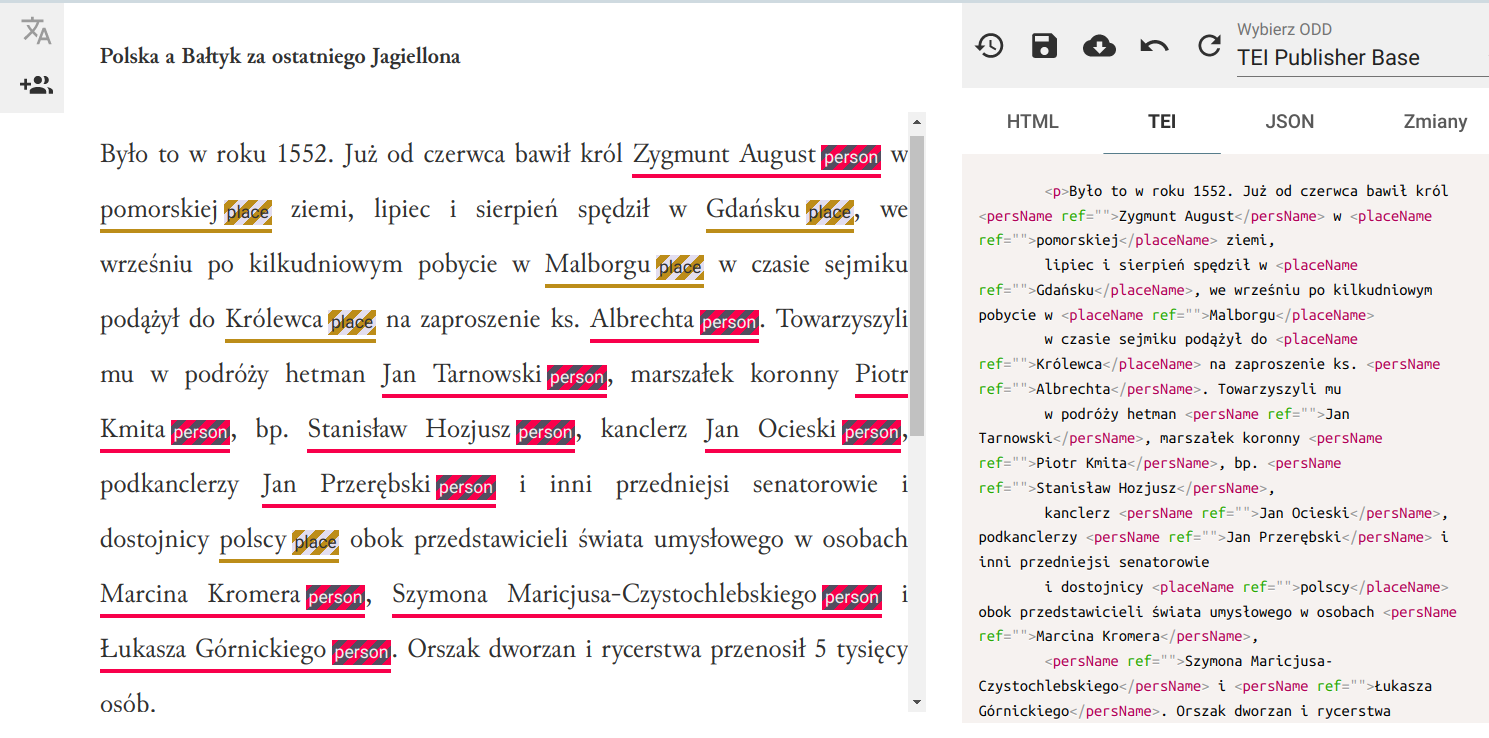
OpenRefine - własny serwis rekoncyliacji/uspójniania (25.09.2022)
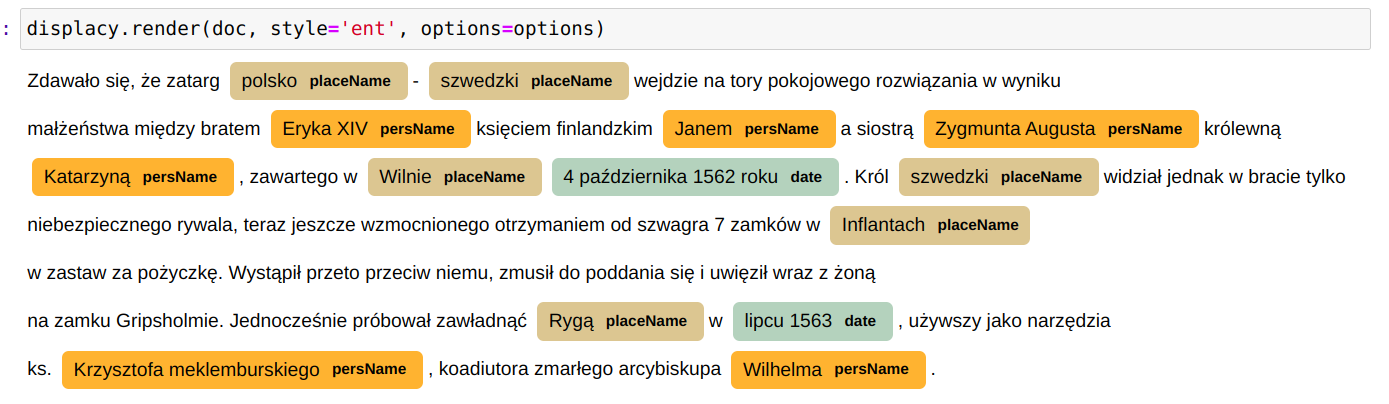
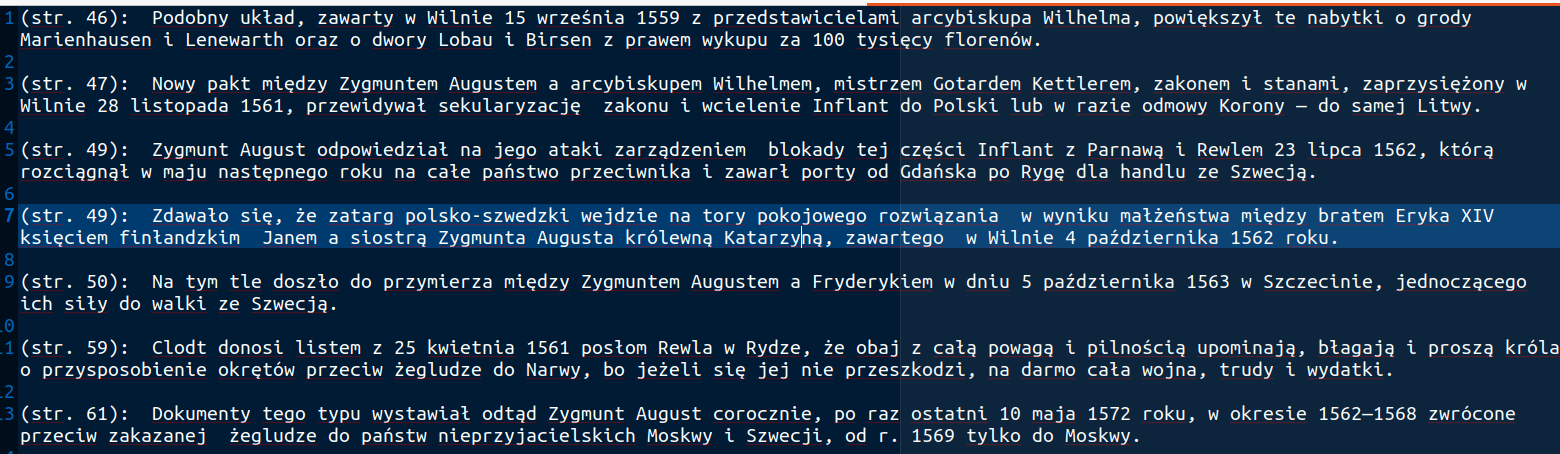
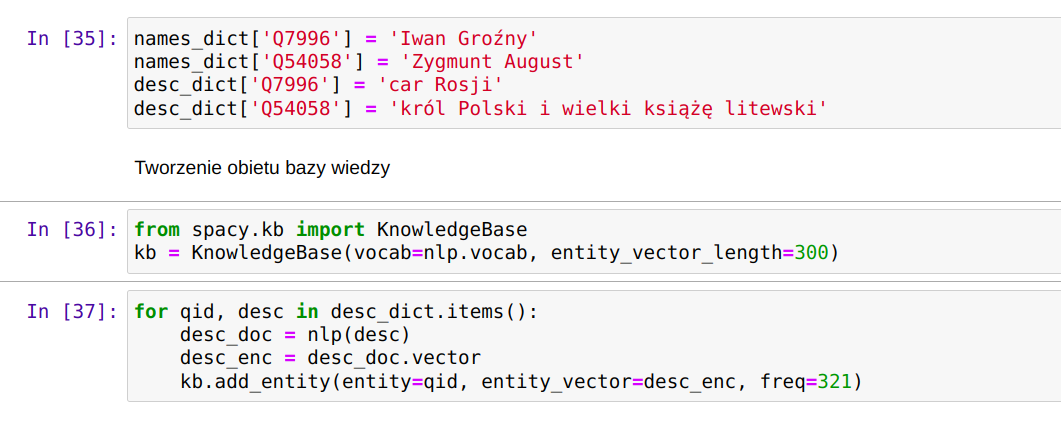
OpenRefine jest popularnym narzędziem do oczyszczania i przekształcania danych. Polecam artykuły na temat OpenRefine: Oczyszczanie danych z użyciem OpenRefine oraz Cleaning Data with OpenRefine Jedną z jego ciekawszych funkcji jest możliwość rekoncyliacji danych przy wykorzystaniu zewnętrznych serwisów udostępniających dane do uspójniania. Często zdarzają się w danych historycznych różnorakie sposoby zapisu imion i nazwisk postaci, lub nazw geograficznych. Nazwy miejscowości mogą występować w brzmieniu współczesnym, w formie używanej w XVI wieku, lub po prostu w formie błędnie zapisanej w źródle. Mechanizm uspójniania w OpenRefine pozwala uzgodnić nazwę występującą w naszych danych z nazwą pochodzącą z pewnego źródła. Np. powiązać "Zbigniewa Oleśnickiego" z identyfikatorem z bazy VIAF, lub powiązać miejscowość Brzozowa (występująca w źródłach także jako Brosoua) z identyfikatorem z Atlasu Historycznego Polski (Brzozowa_sdc_krk).
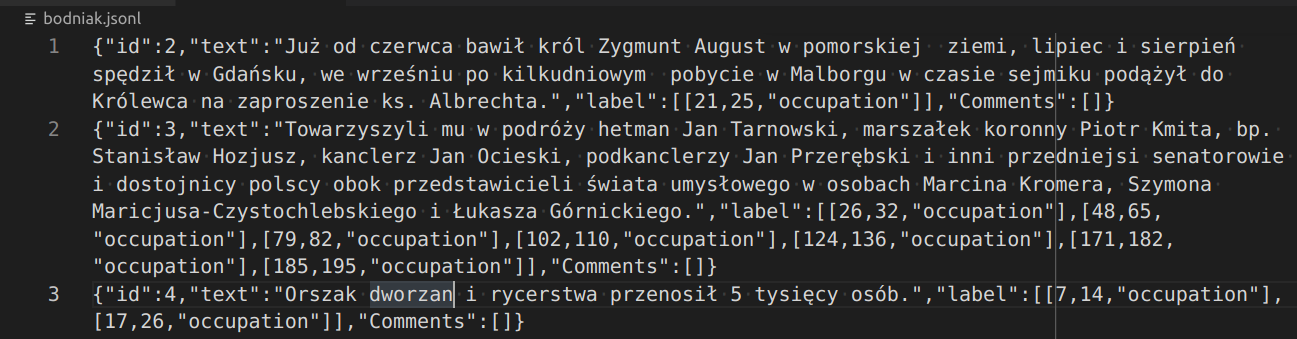
Problemem może być znalezienie odpowiedniego serwisu rekoncyliacji. O ile popularne źródła w rodzaju VIAF czy wikidata.org są dostępne Lista dostępnych serwerów rekoncyliacji. , o tyle uspójnianie z bazą miejscowości AHP lub naszą lokalną bazą osób może wymagać uruchomienia własnego serwisu. Nie jest to jednak takie trudne, istnieją bowiem gotowe narzędzia, które można wykorzystać do tego celu. Jednym z nich jest Reconcile-csv udostępniony (na otwartej licencji BSD-2) na stronie Open Knowledge Lab. Program ten pozwala na dopasowanie szukanej przez nas nazwy do nazw w swojej bazie poprzez mechanizm przybliżonego (rozmytego) porównywania (fuzzy matching), nazwy nie muszą być identyczne, mogą być podobne, program będzie wówczas proponował listę zbliżonych do podanej nazw wraz ze współczynnikiem podobieństwa. Bazą dla Reconcile-csv jest plik tekstowy w formacie CSV.
Program jest plikiem *.jar, (warto pobrać z githuba też plik index.html.tpl, który jest szablonem wyświetlanym jako główna strona serwisu) do uruchomienia potrzebuje więc zainstalowanej Javy (JRE), potrzebny jest oczywiście plik CSV z danymi (plik w którym każdy wiersz jest rekordem danych, pola rozdzielone są przecinkami a pierwszy wiersz zawiera nazwy kolumn).
Polecenie uruchamiające serwer:
java -Xmx2g -jar reconcile-csv-0.1.2.jar plik.csv search_column id_column
gdzie plik.csv to nazwa naszego pliku z danymi, search_columm
to nazwa pola w pliku z danymi, które będzie służyło do rekoncyliacji w OpenRefine,
id_column to nazwa pola w pliku z danymi, które zawiera jednoznaczny identyfikator danych.
Po uruchomieniu serwis dostępny jest pod adresem http://localhost:8000/reconcile, i taki adres należy wprowadzić w OpenRefine (zwraca on zawartość w formacie json, czytelną dla programu - odbiorcy danych z serwisu). Adres główny serwisu (http://localhost:8000) wyświetli o nim podstawowe informacje w formie czytelnej dla człowieka.
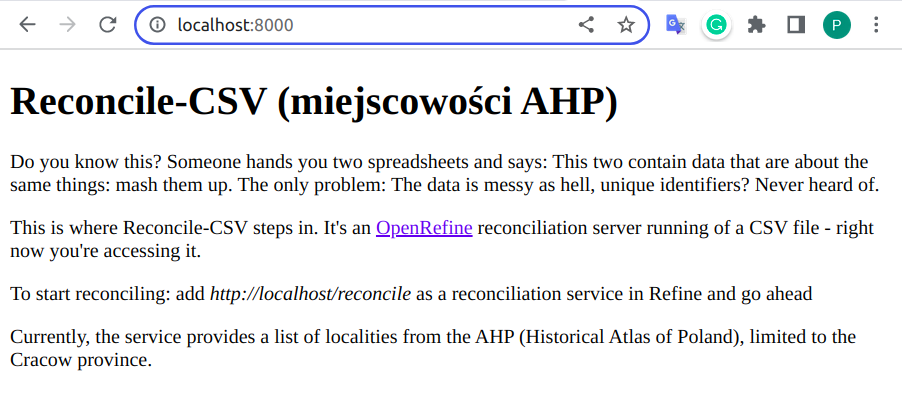
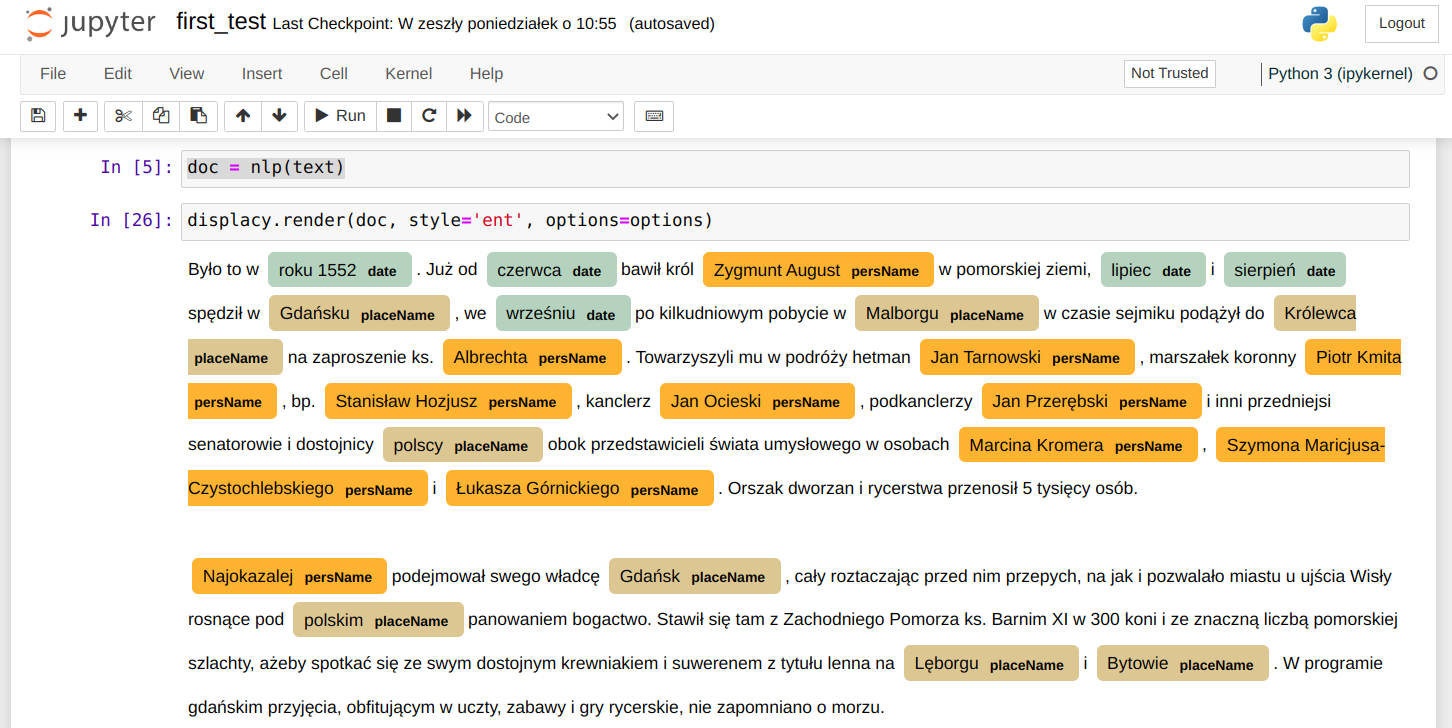
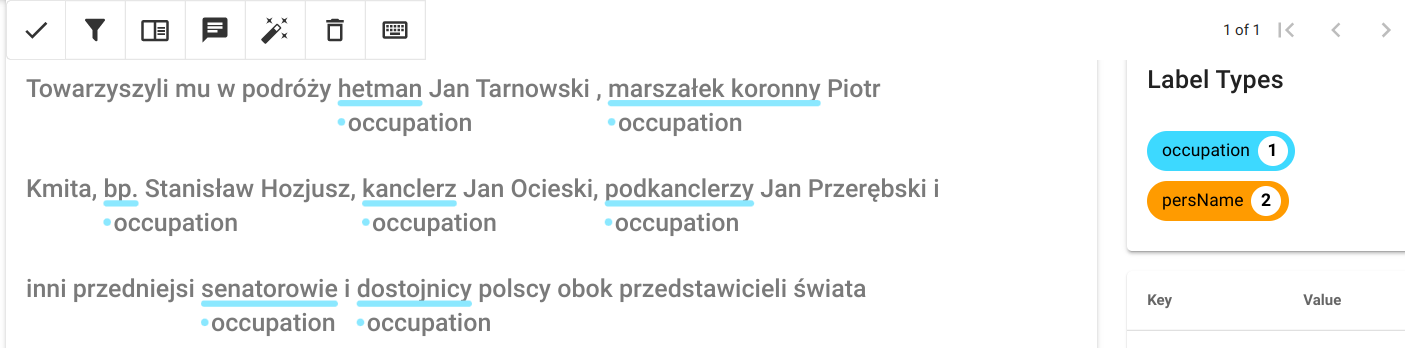
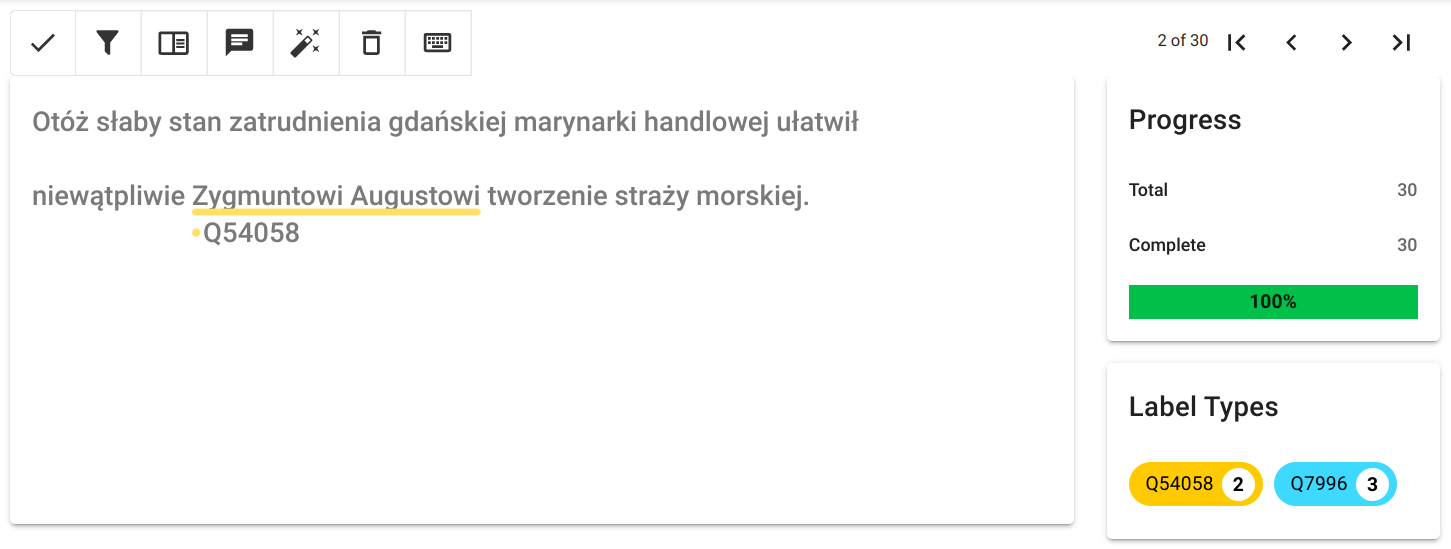
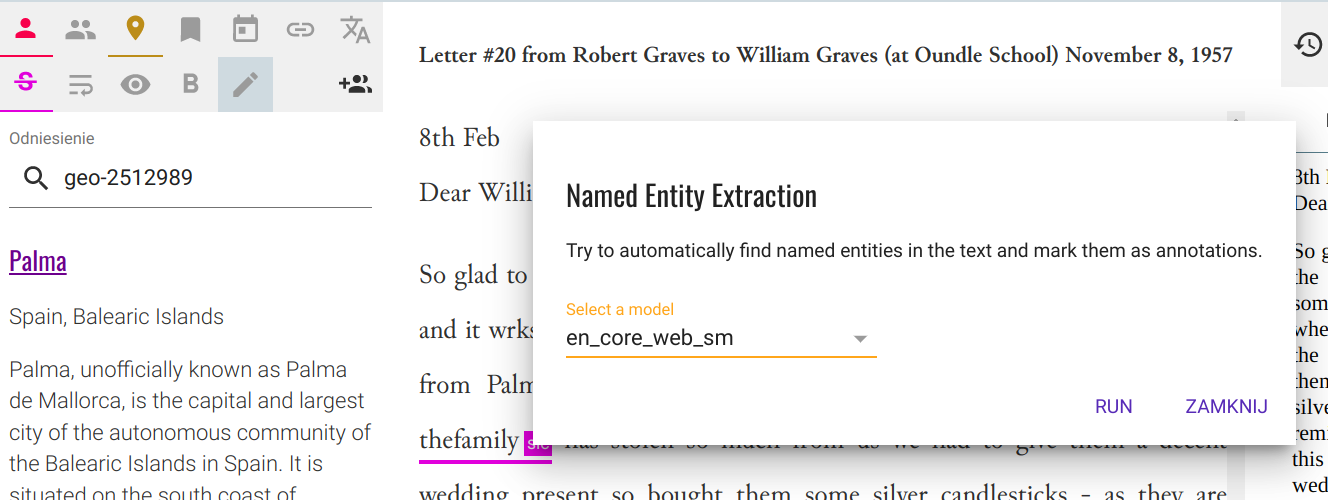
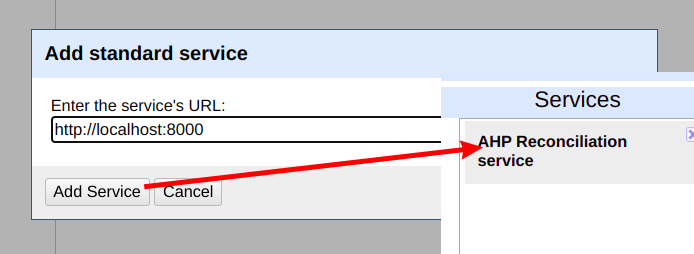
Lokalny serwis rekoncyliacji podłącza się do OpenRefine podobnie jak serwisy zewnętrzne, po uruchomieniu rekoncyliacji na wybranej kolumnie danych przycisk Add Standard Service wyświetli okienko w którym można podać adres serwisu, zaakceptowany serwis pojawi się na liście. Standardowa nazwa serwisu będzie różnić się od pokazanej na ilustracji i wygląda tak: 'CSV Reconciliation service'. Jest niestety zaszyta w kodzie źródłowym Reconcile-csv i jej zmiana wymaga rekompilacji programu (zob. dalszą część artykułu).
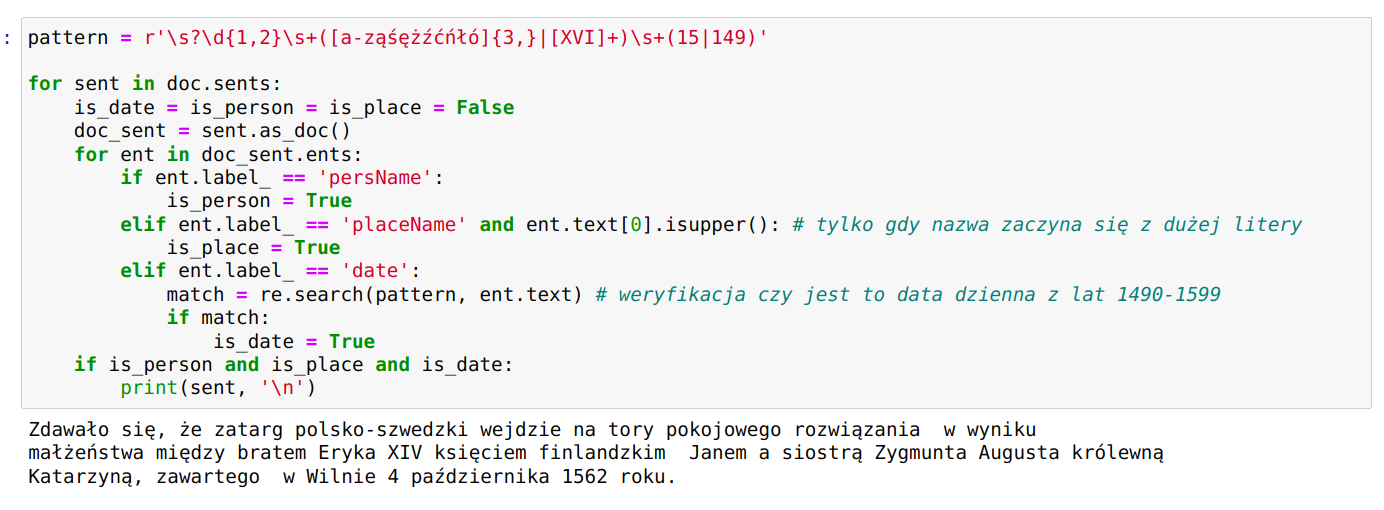
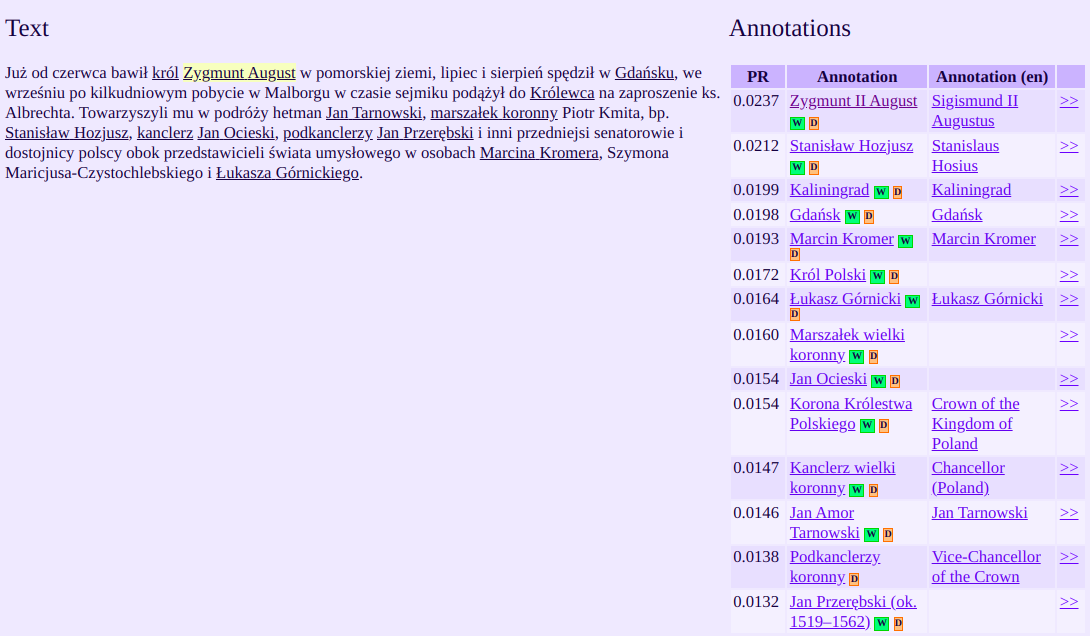
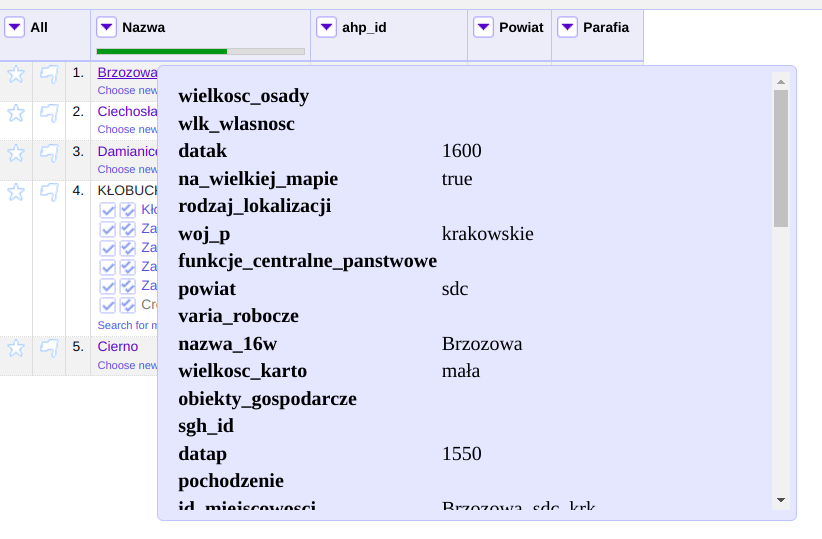
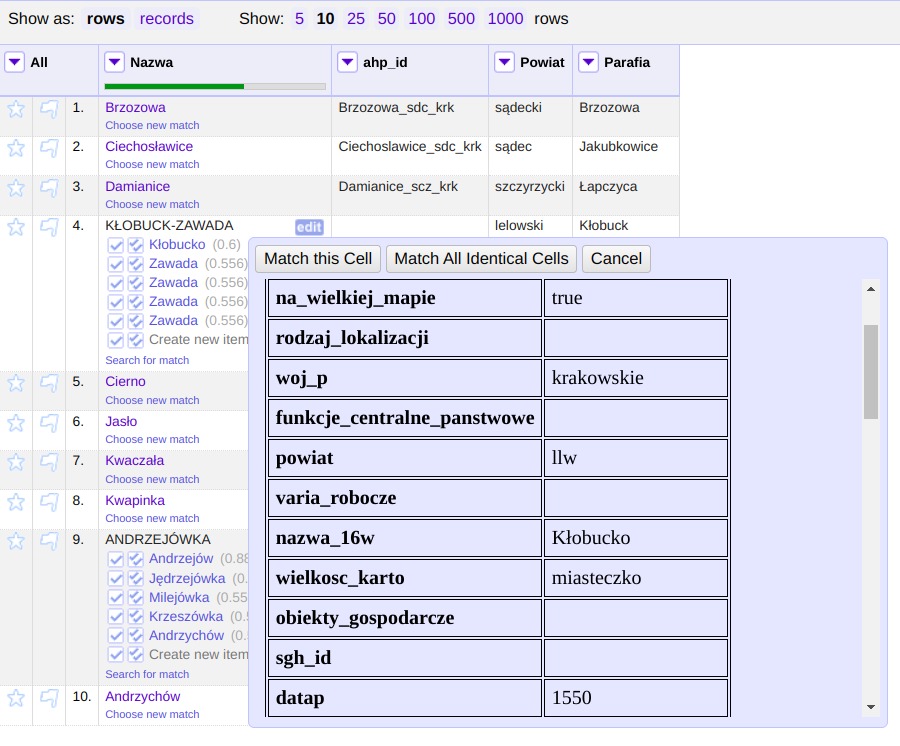
Można wówczas rozpocząć proces uspójniania. Dane które według mechanizmu zostały pewnie dopasowane (współczynnik > 0.85) zostaną od razu przypisane do komórek kolumny dla której przeprowadzamy rekoncyliację, w innych przypadkach wyświetlona zostanie lista wraz z wartościami dopasowania. Dla każdej z pozycji można wyświetlić informacje z pliku csv będącego źródłem danych serwisu, na przykładzie poniżej są to dane miejscowości z Atlasu Historycznego Polski. Dostępne publicznie na licencji CC BY-ND 4.0: AHP 2.0 (IH PAN).
Jak zmodyfikować program reconcile-csv:
zarówno zmiana nazwy serwisu (nazwy wyświetlanej w OpenRefine), jak i dostosowanie programu
Reconcile-csv do pracy na serwerze, wymaga zmian w jego kodzie źródłowym
Repozytorium aplikacji w serwisie
github.
a w związku z tym pewnych umiejętności 'programistycznych'.
Sama zmiana nazwy serwisu wymaga jednak tylko modyfikacji 50 wiersza pliku
/src/reconcile_csv/core.clj: {:name "CSV Reconciliation service",
zmiany tekstu "CSV Reconciliation service" na nowy i rekompilacji programu.
Aplikacja została stworzona w języku clojure. Najłatwiejszym sposobem zarządzania i kompilacji projektu
w języku clojure jest użycie systemu
Leiningen, który w systemie
Ubuntu można zainstalować poleceniem: sudo apt install leiningen.
Rekompilacja projektu Reconcile-csv i budowa nowego pliku *.jar sprowadza się do
uruchomienia polecenia: lein uberjar w katalogu z plikiem project.cli,
skompilowany plik *.jar powinien znajdować się w podkatalogu /target.
Modyfikacja kodu i rekompilacja za każdym razem kiedy chcemy zmienić np. nazwę serwisu
rekoncyliacji wyświetlaną w OpenRefine może być jednak dość niewygodna. Dlatego przygotowałem małą
modyfikację programu reconcile-cvs która obsługuje cztery dodatkowe parametry uruchamiania z linii komend:
adres_serwera, port, nazwa_serwisu_rekoncyliacji i nazwa_typu.
W razie potrzeby wystawiania naszego serwisu na serwerze dostępnym w internecie
można to zrobić za pośrednictwem serwera nginx, który będzie służył jako proxy dla wbudowanego w reconlice-csv
jetty, wówczas reconcile-csv będzie pracował pod adresem np. localhost:8080, a o obsługę żądań zewnętrznych
zadba nginx.
Dodatkowo serwis wyświetla trochę bardziej czytelny podgląd danych z pliku csv, podczas
uspójniania (widoczne ramki tabeli).
Przykładowe wywołanie:
java -Xmx2g -jar reconcile-csv-0.1.2.jar plik.csv search_column id_column "http://moj_serwer.org" "80" "Miasta-Osoby Serwis Rekoncyliacji" "miasta_osoby"
lub (obecnie port inny niż 80 trzeba podać także w adresie serwera):
java -Xmx2g -jar reconcile-csv-0.1.2.jar plik.csv search_column id_column "http://localhost:8000" "8000" "Miasta-Osoby Serwis Rekoncyliacji" "miasta_osoby"
Kod źródłowy modyfikacji można pobrać z github, skompilowany plik jar również: releases.